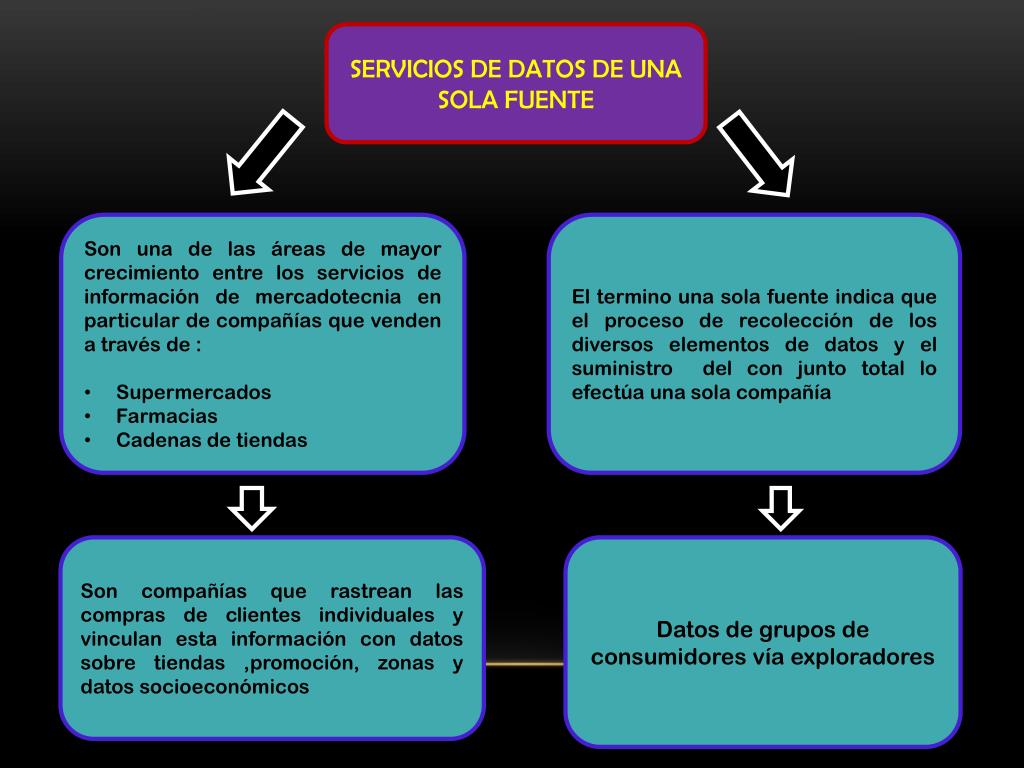
Servicios De Datos De Una Sola Fuente

Vamos a explicar qué son los Servicios de Datos de una Sola Fuente y cómo funcionan. Piensa en ellos como una forma organizada de acceder a la información.
Paso 1: Identificar las Fuentes de Datos
Primero, necesitamos saber de dónde viene la información. Pueden ser bases de datos, archivos Excel, servicios web o incluso documentos de texto. Imagina que tienes datos de clientes en un archivo Excel y datos de ventas en una base de datos SQL.
El primer paso es simplemente hacer una lista de todas esas fuentes. Escribe dónde están ubicadas y qué tipo de información contienen. Esto te dará una visión general de la situación.
Must Read
Paso 2: Centralizar el Acceso a los Datos
Ahora, en lugar de acceder a cada fuente individualmente, creamos un punto central. Este punto central es como un "traductor" que sabe cómo hablar con todas las fuentes diferentes. Este punto central se llama un Data Lake.
Podemos usar herramientas como Apache Kafka o Apache NiFi para centralizar los datos. Estas herramientas toman los datos de las diferentes fuentes y los envían a una ubicación común. Piensa en Kafka como un mensajero que entrega los datos a un buzón central.
Es crucial que el Data Lake tenga la capacidad de almacenar los diferentes tipos de datos. Por ejemplo, textos, numeros y fechas.
Paso 3: Transformar y Limpiar los Datos
Los datos de diferentes fuentes a menudo están en formatos diferentes y pueden contener errores. Por ejemplo, una fuente puede usar "EE. UU." para Estados Unidos y otra puede usar "USA". O una fecha estar en diferentes formatos.

Necesitamos "limpiar" y transformar los datos para que sean consistentes y útiles. Este proceso se llama ETL (Extract, Transform, Load). Extraemos los datos, los transformamos para que tengan un formato uniforme y los cargamos en una ubicación centralizada.
Utilizamos herramientas como Apache Spark o Python con bibliotecas como Pandas para realizar esta transformación. Por ejemplo, podemos usar Python para estandarizar los formatos de fecha.
Paso 4: Crear una Vista Unificada de los Datos
Una vez que los datos están limpios y transformados, creamos una vista unificada. Esto significa que presentamos los datos como si vinieran de una sola fuente, aunque en realidad provengan de muchas fuentes diferentes.
Podemos crear Data Warehouses o Data Marts. Un Data Warehouse es un gran repositorio de datos para toda la organización. Un Data Mart es una porción más pequeña y enfocada del Data Warehouse para un departamento específico.
Imagina que creamos una tabla que combina datos de clientes del archivo Excel con datos de ventas de la base de datos. Ahora, podemos ver las ventas totales de cada cliente en un solo lugar.

Paso 5: Exponer los Datos a los Usuarios
Finalmente, necesitamos permitir que los usuarios accedan a los datos de manera fácil. Esto puede hacerse a través de paneles de control (dashboards), informes o APIs (interfaces de programación de aplicaciones).
Herramientas como Tableau o Power BI permiten a los usuarios crear paneles de control interactivos y visualizaciones de datos. Los usuarios pueden explorar los datos y obtener información valiosa sin tener que preocuparse por las complejidades de las fuentes de datos subyacentes. Estos datos ahora son un servicio.
Una API permite que otras aplicaciones accedan a los datos de forma programática. Por ejemplo, una aplicación móvil podría usar una API para mostrar los datos de ventas en tiempo real. Una API es como un "menú" que permite a las aplicaciones solicitar datos específicos.

