Analisis De Regresion Y Correlacion Estadistica

Comenzaremos abordando el análisis de regresión y correlación estadística paso a paso.
Parte 1: Regresión Lineal Simple
Primero, identificaremos la variable dependiente (Y) y la variable independiente (X). Luego, calcularemos la pendiente (b) de la línea de regresión.
La fórmula para la pendiente es: b = Σ[(Xi - X̄)(Yi - Ȳ)] / Σ[(Xi - X̄)²]. X̄ e Ȳ son las medias de X e Y, respectivamente. Necesitamos calcular estas medias primero.
Must Read
Después, calcularemos el intercepto (a). La fórmula para el intercepto es: a = Ȳ - bX̄. Ya tenemos Ȳ, X̄ y b de los pasos anteriores.
Finalmente, construiremos la ecuación de la línea de regresión: Ŷ = a + bX. Esta ecuación nos permite predecir valores de Y dado un valor de X.
Parte 2: Coeficiente de Correlación (r)
Ahora calcularemos el coeficiente de correlación de Pearson (r). Este coeficiente mide la fuerza y dirección de la relación lineal entre X e Y.
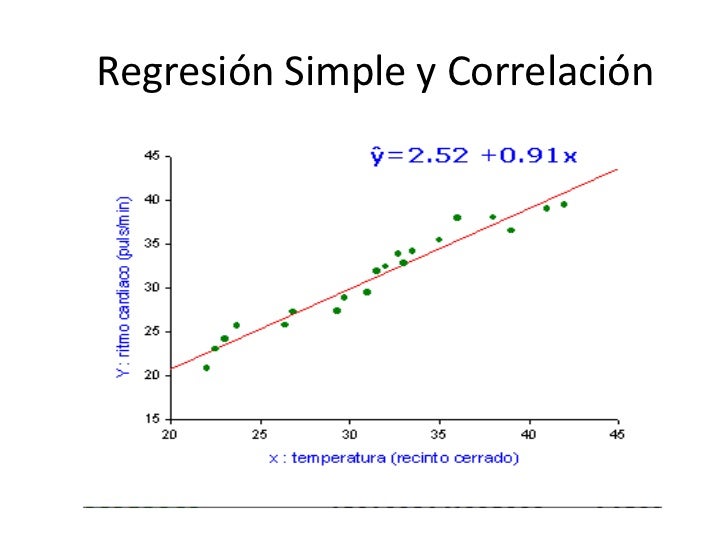
La fórmula para r es: r = Σ[(Xi - X̄)(Yi - Ȳ)] / √{Σ[(Xi - X̄)²] Σ[(Yi - Ȳ)²]}. Usaremos los valores calculados en la Parte 1.
El valor de r varía entre -1 y +1. Un valor cercano a +1 indica una correlación positiva fuerte. Un valor cercano a -1 indica una correlación negativa fuerte. Un valor cercano a 0 indica una correlación débil o nula.
Parte 3: Coeficiente de Determinación (r²)
Calcularemos el coeficiente de determinación (r²). Este coeficiente indica la proporción de la varianza en Y que es explicada por X.

Simplemente elevaremos al cuadrado el coeficiente de correlación: r² = r². Es decir, el resultado de la sección anterior.
r² varía entre 0 y 1. Un valor cercano a 1 indica que el modelo de regresión explica una gran proporción de la variabilidad en Y. Un valor cercano a 0 indica que el modelo explica poco de la variabilidad.
Parte 4: Análisis de Residuos
Es importante analizar los residuos para verificar la validez del modelo de regresión. Los residuos son las diferencias entre los valores observados de Y y los valores predichos (Ŷ).
Calculamos los residuos: ei = Yi - Ŷi. Para cada punto de datos, restamos el valor predicho por el modelo al valor real.

Luego, graficamos los residuos contra los valores predichos (Ŷ). Buscamos patrones en el gráfico. Un patrón aleatorio sugiere que el modelo es apropiado.
Si observamos patrones no aleatorios (como una forma de embudo o una curva), esto indica que los supuestos del modelo de regresión lineal no se cumplen. Esto podría requerir una transformación de los datos o el uso de un modelo diferente.
Parte 5: Interpretación de los Resultados
Una vez que hemos calculado b, r y r², y analizado los residuos, podemos interpretar los resultados.

La pendiente (b) nos dice cuánto cambia Y por cada unidad de cambio en X. El signo de b indica la dirección de la relación (positiva o negativa).
El coeficiente de correlación (r) nos dice la fuerza y dirección de la relación lineal. El coeficiente de determinación (r²) nos dice qué tan bien el modelo explica la variabilidad en Y.
Finalmente, el análisis de residuos nos da información sobre la validez del modelo.
Resumen: Siguiendo estos pasos, podemos realizar un análisis completo de regresión y correlación, obteniendo información valiosa sobre la relación entre dos variables.